
A global leader in ESL(Electronic Shelf Labeling) technology innovation with its own manufacturing facilities, the company excels in reducing development time, maintaining strict quality control, optimizing supply chains, and ensuring cost competitiveness. Built on a strong technological foundation and industry expertise, the company invests heavily in innovation, design, and product development, fostering long-term relationships with customers and partners worldwide.
The Problem
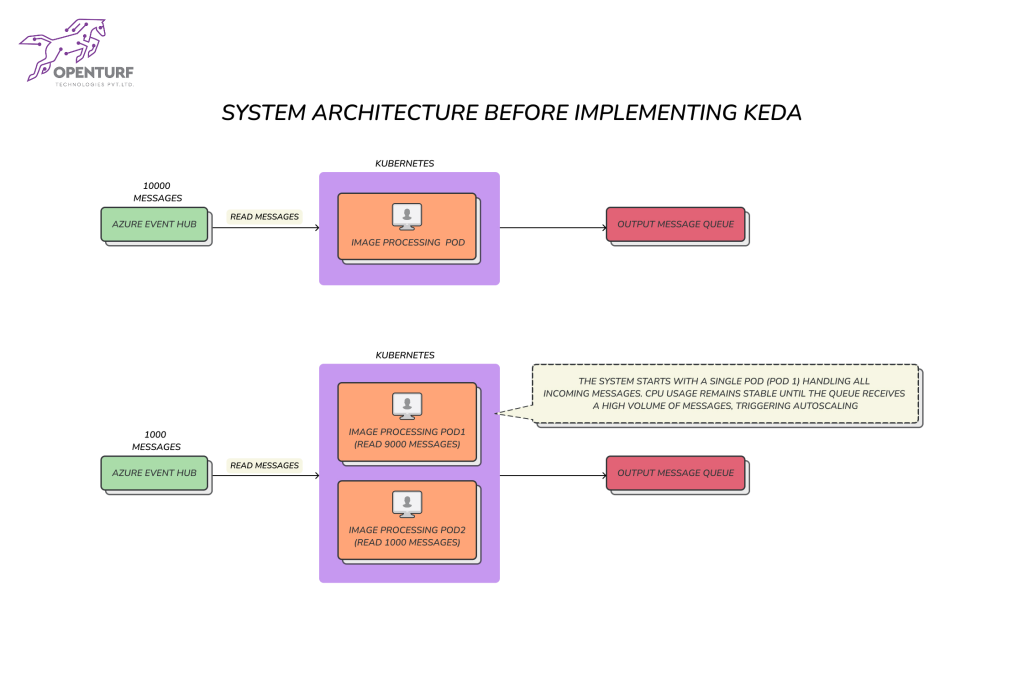
The ESL, a SaaS solution and microservice-architected system built on Microsoft Azure, faced significant challenges in its critical flow of generating image-based labels and pushing them to devices. The service consumed requests from the Azure Event Hub queue, but the customer encountered several issues impacting performance and stability. The client’s image generation microservice was falling short of its performance goal, only generating 650 images per second, far below the required 1200 images per second. This gap in performance was caused by several challenges:
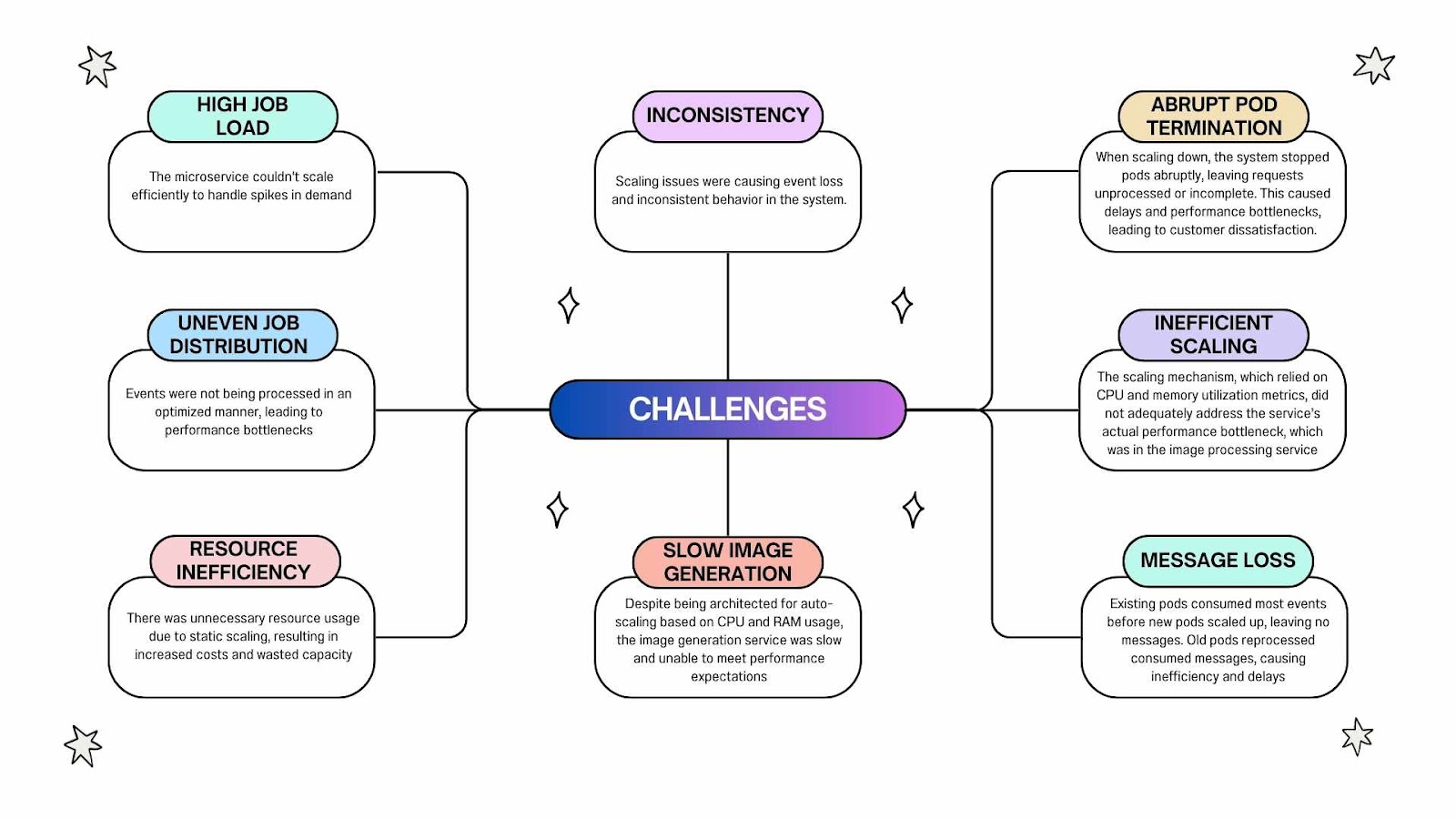
- High job load: The microservice couldn’t scale efficiently to handle spikes in demand.
- Uneven job distribution: Events were not being processed in an optimized manner, leading to performance bottlenecks.
- Resource inefficiency: There was unnecessary resource usage due to static scaling, resulting in increased costs and wasted capacity.
- Event loss and inconsistency: Scaling issues were causing event loss and inconsistent behavior in the system.
- Slow Image Generation: Despite being architected for auto-scaling based on CPU and RAM usage, the image generation service was slow and unable to meet performance expectations.
- Abrupt Pod Termination: When scaling down, the system stopped pods abruptly, leaving requests unprocessed or incomplete. This caused delays and performance bottlenecks, leading to customer dissatisfaction.
- Inefficient Scaling: The scaling mechanism, which relied on CPU and memory utilization metrics, did not adequately address the service’s actual performance bottleneck, which was in the image processing service.
- Queue Consumption and Message Loss: Existing pods consumed a large number of events from the Azure Event Hub Queue, and by the time new pods were scaled up, there were no messages left in the queue. This meant that old pods continued to process already-consumed messages, which was time-consuming and inefficient.
The client needed a solution that could enhance scalability, optimize resource allocation, and eliminate performance bottlenecks in the image generation process.
The Analysis
The client engaged with OpenTurf Technologies, a leader in software development and performance engineering, to analyze the existing architecture and propose a solution. OpenTurf’s team conducted a thorough assessment of the microservice, identifying the root causes of the performance bottlenecks. The client’s existing architecture was struggling with slow performance, specifically in the generation of images, due to high job loads, uneven job distribution, and limitations in the system’s design.
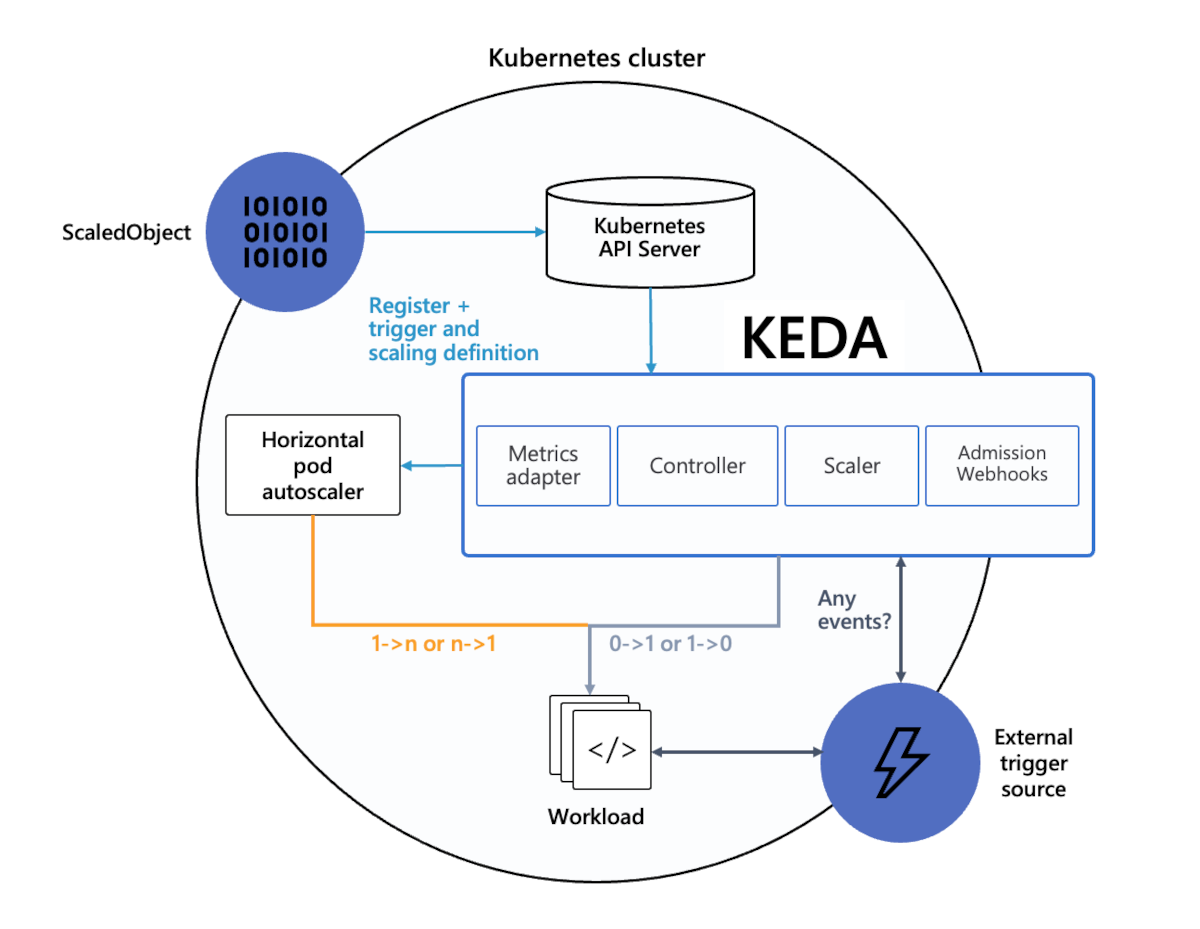
OpenTurf proposed a solution leveraging Kubernetes-based Event-Driven Autoscaler (KEDA) to optimize their system architecture, improve performance, and reduce costs.
KEDA Architecture:
The Solution
OpenTurf recommended the integration of KEDA (Kubernetes-based Event-Driven Autoscaler) to address the client’s scalability and performance challenges. KEDA allows for event-driven scaling by adjusting resources dynamically based on event load. The proposed solution had the following key components:
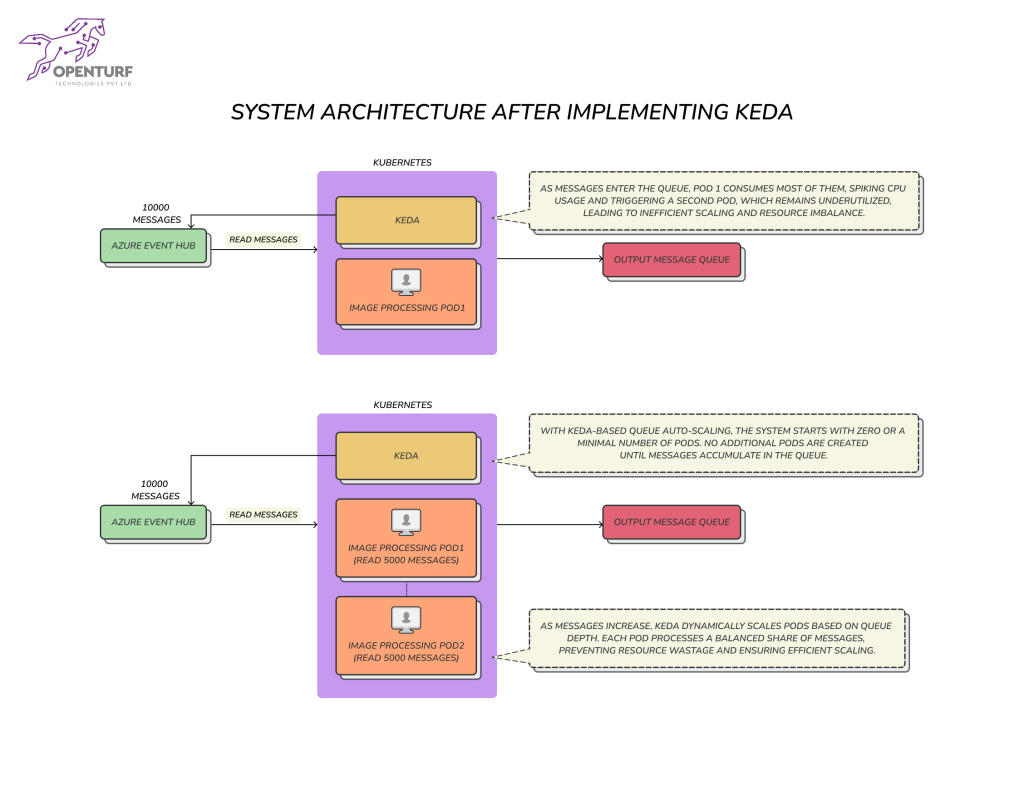
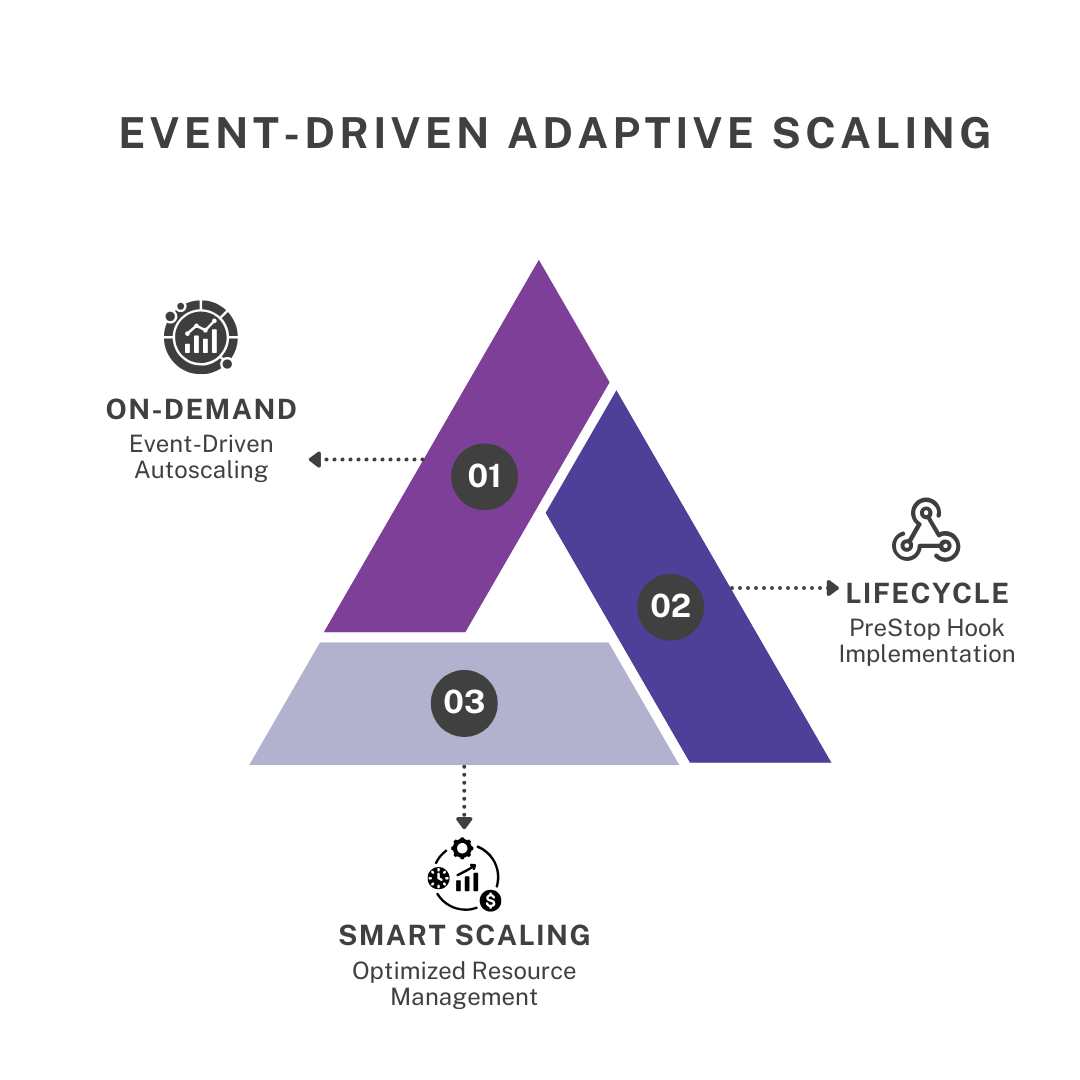
Event-Driven Autoscaling: KEDA was configured to monitor the event queue for image generation requests. As the queue grew, KEDA automatically scaled up the number of image generation microservice instances and when the queue decreased, KEDA scaled down the instances, optimizing resource utilization.It was determined that scaling based on the queue size, rather than resource utilization metrics like CPU and memory, would be more effective in addressing the service’s performance bottleneck.
PreStop Hook Implementation: Since KEDA does not handle SIGHUP signals for scale-down, OpenTurf implemented a preStop hook in Kubernetes to prevent event loss during scale-down, ensuring a seamless transition without impacting performance. This hook ensured that before a microservice instance was scaled down, it would complete processing any ongoing image generation requests, preventing event loss and ensuring data consistency. This addressed a critical gap in KEDA’s default behavior, which doesn’t handle graceful shutdown for scale-down events.
Optimized Resource Management: With KEDA, the system would dynamically scale resources based on actual event loads rather than maintaining static resource allocation. This resulted in significant cost savings by reducing unnecessary resource consumption.
The client successfully met its performance requirements and resolved the challenges that were negatively impacting the system, resulting in a more reliable and efficient image generation.
The Result
After implementing KEDA, the following performance achievements were attained,
Dramatic Performance Boost: The image generation microservice experienced a 150% performance increase, going from 650 images per second to 1600 images per second. This surpassed the client’s target of 1200 images per second. The system could now efficiently process 6 million images per hour. The image generation service was able to meet its performance requirements, with faster processing times and improved overall responsiveness.
Significant Cost Savings: The dynamic scaling capabilities of KEDA, coupled with the optimized resource management, resulted in substantial cost reductions. The client no longer had to pay for over-provisioned resources.
Dynamic Scaling: The automatic scale-up and scale-down of resources based on event load helped avoid unnecessary resource consumption.
Resource Optimization: The system now efficiently manages resources, reducing operational costs while maintaining high performance.
Stable Pod Scaling: Pods were now scaling based on the queue size, which ensured that the system could efficiently handle incoming requests without overloading or underutilizing resources.
Request Integrity: The preStop and postStart lifecycle hooks effectively prevented requests from being lost during pod scaling, ensuring that all requests were processed successfully and without disruption.
The successful integration of KEDA into the client’s ESL architecture demonstrates the power of event-driven autoscaling in optimizing cloud-native applications.This case study highlights the power of Kubernetes-based solutions like KEDA in optimizing cloud-native applications, ensuring scalability, efficiency, and performance and OpenTurf’s expertise in performance engineering that enabled the client to overcome critical performance bottlenecks, achieve significant cost savings, and improve the reliability of their image generation process. OpenTurf delivers impactful solutions that help clients scale their operations efficiently and achieve their business goals.
References and Further Reading:
https://keda.sh/docs/2.16/concepts/
https://kubernetes.io/docs/concepts/containers/container-lifecycle-hooks/